Qu'est-ce que la RAG (Retrieval-Augmented Generation) ?
Comment fonctionne la RAG : la technologie qui améliore les modèles de langage de grande taille avec des informations actualisées et contextuelles

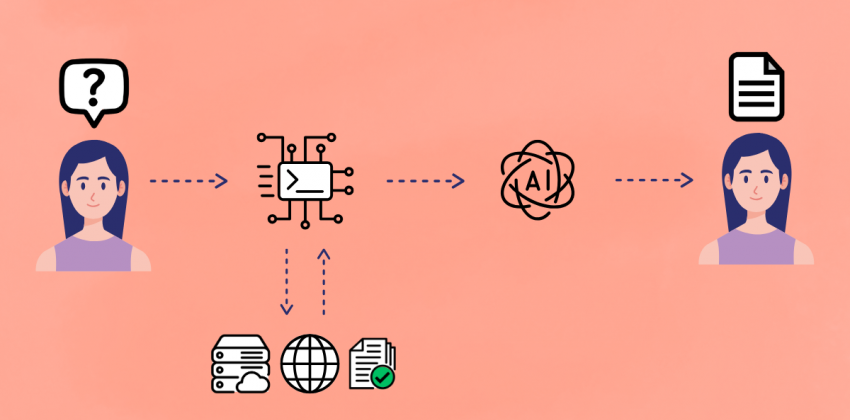
Dans le paysage en constante évolution de l’intelligence artificielle, les Large Language Models (LLM) ont démontré des capacités remarquables à générer du texte cohérent et pertinent dans un contexte donné. Cependant, même les modèles les plus avancés peuvent rencontrer des problèmes tels que les « hallucinations » (informations plausibles mais erronées) ou être limités aux connaissances acquises pendant leur entraînement.
C’est dans ce contexte que la Retrieval-Augmented Generation (RAG) joue un rôle clé. Il s’agit d’une technique innovante qui révolutionne notre façon d’interagir avec les LLM, en les rendant plus précis, fiables et actualisés. RAG devient une approche centrale pour développer des systèmes conversationnels, des assistants intelligents et des moteurs de question-réponse capables de combiner la puissance des modèles linguistiques avec l’accès à des sources de connaissance externes.
Dans cet article, nous allons explorer en détail ce qu’est la RAG, comment elle fonctionne, pourquoi elle est si importante et en quoi elle se distingue de techniques comme la recherche sémantique.
Table des matières
- Qu’est-ce que la Retrieval-Augmented Generation (RAG) ?
- Comment fonctionne la Retrieval-Augmented Generation ?
- RAG et les modèles de langage de grande taille (LLM)
- Quelle est la différence entre la RAG et la recherche sémantique ?
- Pourquoi utiliser la RAG et pourquoi est-elle si importante ?
- Quels sont les avantages de la Retrieval-Augmented Generation ?
Qu’est-ce que la Retrieval-Augmented Generation (RAG) ?
La Retrieval-Augmented Generation (RAG) est une technique qui améliore les capacités des modèles linguistiques à générer des réponses précises et documentées, en récupérant des informations issues d’une base de connaissances externe et fiable avant de produire une réponse finale.
Elle combine deux composantes fondamentales du traitement du langage naturel :
- Retrieval (récupération) : l’accès à une base de connaissances externe (documents, bases de données, articles, etc.) pertinente par rapport à une requête ou un prompt ;
- Generation (génération) : la production d’une réponse cohérente et contextuelle à l’aide d’un modèle linguistique (généralement un LLM) alimenté par les résultats récupérés.
Au lieu de s’appuyer uniquement sur les connaissances « mémorisées » lors de la phase d’entraînement, la RAG recherche activement des données pertinentes dans un corpus documentaire, une base de données ou sur le web, et les utilise comme contexte supplémentaire pour guider la génération du LLM, améliorant ainsi la précision, l’actualité et la pertinence des réponses.
Comment fonctionne la Retrieval-Augmented Generation ?
Le processus RAG peut être résumé en cinq grandes étapes :
- Indexation – Les données externes sont converties en représentations numériques (embeddings). Ces vecteurs capturent le sens sémantique du contenu et sont stockés dans des bases de données vectorielles optimisées pour la recherche par similarité.
- Embedding de la requête – Lorsqu’un utilisateur saisit une requête ou un prompt, celle-ci est transformée en vecteur numérique à l’aide du même modèle d’encodage que celui utilisé pour les documents.
- Récupération de documents – L’embedding de la requête est utilisé pour rechercher dans l’index vectoriel les documents ou fragments de texte les plus proches sémantiquement. Ce processus permet d’identifier rapidement les informations les plus pertinentes par rapport à la requête.
- Augmentation – Les fragments d’information récupérés sont fournis au LLM comme contexte supplémentaire, en complément de la requête de l’utilisateur.
- Génération conditionnée – Le LLM, désormais enrichi de ces données spécifiques et actualisées, utilise à la fois ses connaissances internes et ce contexte pour générer une réponse plus précise, pertinente et sans hallucinations. À ce stade, le modèle ne fait pas que reformuler les informations : il les synthétise, les réorganise et les adapte pour former une réponse naturelle et cohérente.
RAG et les modèles de langage de grande taille (LLM)
Les LLM comme GPT-4 ou Claude possèdent de grandes capacités de compréhension du langage naturel, de résumé, de traduction ou de génération de texte, mais ils sont limités par la fenêtre temporelle de leur entraînement et le nombre de tokens qu’ils peuvent mémoriser. En d’autres termes, leur savoir est limité au corpus utilisé lors de l’entraînement, qui peut être obsolète ou inadapté à certains domaines.
Grâce à l’approche RAG, ces limites peuvent être dépassées :
- Accès à des informations mises à jour en temps réel (articles de presse, bases de données internes, documents d’entreprise, etc.) ;
- Réduction des hallucinations (affirmations incorrectes ou inventées) ;
- Diminution des biais liés aux données d’entraînement ;
- Possibilité de répondre à des questions spécifiques à un domaine (ex. : documentation interne d’une entreprise) sans nécessiter de réentraînement ;
- Possibilité d’inclure des références vers les sources utilisées, renforçant ainsi la transparence et la confiance.
En résumé, RAG étend la mémoire des LLM et en fait des outils de recherche et de génération plus fiables et personnalisables.
Quelle est la différence entre la RAG et la recherche sémantique ?
Ces deux techniques reposent sur la récupération sémantique de contenus, mais leurs objectifs sont différents :
| Caractéristique | Recherche sémantique | Retrieval-Augmented Generation |
|---|---|---|
| Sortie | Liste de documents ou fragments | Réponse générée en langage naturel |
| Modèle de génération | Absent | Présent (ex. : LLM comme GPT, BART) |
| Finalité | Lecture et exploration par l’utilisateur | Réponse autonome et élaborée par le système |
| Personnalisation | Limitée | Élevée : optimisable par domaine ou contexte |
La recherche sémantique vise à retrouver les documents les plus pertinents pour une requête en tenant compte du sens. La RAG, quant à elle, ne se contente pas de restituer des résultats : elle les synthétise et les contextualise, offrant une expérience proche d’un échange avec un expert.
Pourquoi utiliser la RAG et pourquoi est-elle si importante ?
L’importance de la Retrieval-Augmented Generation repose sur plusieurs avantages majeurs :
- Contexte à jour
Les réponses peuvent se baser sur du contenu récent sans besoin de réentraînement du modèle. - Sources vérifiables
Les contenus générés peuvent être tracés et associés à des documents réels et accessibles. - Réduction des hallucinations
Le contexte externe permet d’ancrer le LLM dans la réalité. - Domaines spécifiques et personnalisés
La RAG facilite l’intégration de bases de connaissance scientifiques, métier ou internes. - Rentabilité
Moins coûteux que le fine-tuning pour actualiser les connaissances.
Elle constitue ainsi une solution idéale dans les cas où la précision, l’actualisation continue et la responsabilité sont essentielles.
Quelques cas d’application
La RAG transforme déjà la manière dont nous interagissons avec l'IA dans divers secteurs, par exemple :
- Médecine : diagnostic assisté à partir de bases de données de recherches cliniques ;
- Droit : analyse de contrats avec références aux lois en vigueur ;
- Recherche académique : Q&R sur des articles scientifiques ;
- Support informatique : assistants résolvant des problèmes techniques via des documentations internes ou forums.
Utiliser la RAG dans les applications de chat
De plus en plus de systèmes de chatbots avancés — assistants juridiques, médicaux ou service client — adoptent l’architecture RAG afin de garantir :
- Des réponses précises basées sur des manuels, des règlements ou des événements récents ;
- La personnalisation des conversations selon l’utilisateur ou l’entreprise ;
- La mise à jour continue du contenu sans toucher au modèle de base.
En pratique, la RAG transforme une simple interface de chat en un véritable agent intelligent et spécialisé.
Quels sont les avantages de la Retrieval-Augmented Generation ?
Voici un résumé des principaux bénéfices de la RAG :
- Accès à des connaissances externes et à jour
- Réduction des hallucinations propres aux LLM autonomes
- Flexibilité et évolutivité sur différentes bases de données
- Traçabilité des sources
- Meilleur contrôle de la qualité des réponses
- Intégration fluide avec les architectures existantes (ex. : API, bases de connaissances)
La RAG représente une avancée majeure pour les LLM, les transformant d’« encyclopédies statiques » en systèmes dynamiques capables d’apprendre en contexte. Grâce à sa capacité à combiner récupération intelligente et génération avancée, elle est destinée à devenir un standard dans les applications professionnelles et grand public où la précision et l’actualité sont essentielles.
Énergie sans carbone pour notre nuage ![]() Low CO2
Low CO2





Openapi SpA Unipersonale - Société soumise à la direction et au contrôle de Open Holding Srl - Viale Filippo Tommaso Marinetti 221 - 00143 Rome - Registre des Entreprises REA 1378273 - Capital social € 50.000,00 entièrement versé – N° TVA IT12485671007 - Code destinataire 'USAL8PV' - PEC : 
Openapi est certifiée : Système de gestion de la qualité UNI EN ISO 9001:2015 - Qualité des données ISO 25012:2014 - Gestion de la sécurité ISO/IEC 27001:2022 - Égalité des sexes selon UNI PdR 125:2022
Tous les prix sont à considérer hors TVA éventuelle, droits de timbre éventuels, frais de secrétariat et/ou taxes ou impôts autrement désignés s'ils sont dus. Tous les logos mentionnés sur le portail sont protégés par des droits d'auteur et appartiennent à leurs propriétaires respectifs.








