APIs synchrones et asynchrones
Ce qu’elles sont, quelles sont les différences et comment les utiliser pour une architecture efficace et évolutive

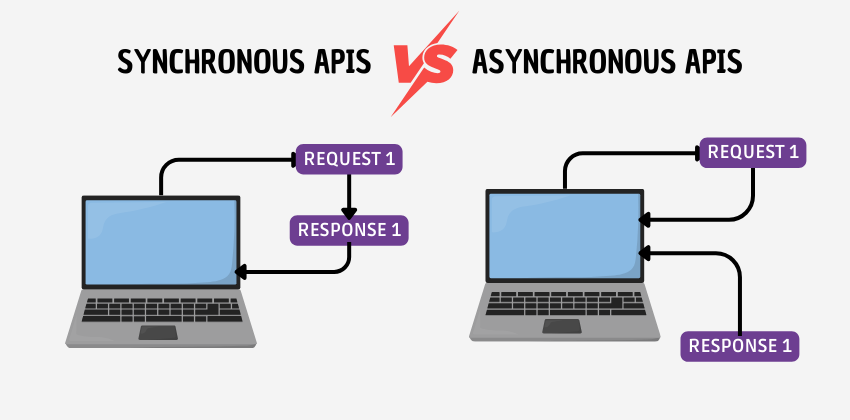
Les API (Application Programming Interface) fonctionnent selon un modèle requête-réponse : lors d’un appel API, le client envoie une requête au serveur, qui lui renvoie ensuite les données demandées ou un message. Ce schéma général peut être décliné en deux modes d’exécution : synchrone et asynchrone.
La distinction entre ces deux modèles n’est pas seulement théorique : elle influence fortement la conception de systèmes évolutifs et performants, ce qui fait de la bonne implémentation des mécanismes d’interaction synchrones et asynchrones une caractéristique fondamentale de toute architecture applicative moderne.
API synchrones : ce qu’elles sont et comment elles fonctionnent
Dans une API synchrone, la communication se fait en temps réel : le client envoie la requête au serveur et attend jusqu’à ce qu’il reçoive la réponse. Durant ce laps de temps, le client ne peut effectuer aucune autre opération ni envoyer de nouvelles requêtes sur le même thread, d’où le terme de mécanisme « bloquant ».
Ce type d’API est idéal pour les opérations rapides, comme la récupération de données de géocodage pour la navigation satellite ou la mise à jour d’une base de données partagée. La réponse du serveur est pratiquement immédiate et contient généralement les données demandées ou la confirmation de l’exécution d’une commande, par exemple la suppression d’une ressource ou l’envoi d’un message.
Les API synchrones sont très courantes dans les microservices web, car elles permettent un retour immédiat et sont faciles à implémenter. En revanche, ce modèle de communication impose que le client attende la réponse du serveur avant de pouvoir faire quoi que ce soit d’autre. Cela signifie qu’il n’est adapté que lorsque le traitement de la réponse ne prend que quelques secondes. Dans certaines applications, comme le téléchargement et l’analyse d’une vidéo volumineuse ou la génération d’un rapport financier, ce mécanisme peut devenir inefficace et constituer un obstacle à la scalabilité.
Qu’est-ce qu’une API asynchrone ?
Contrairement aux API synchrones, les API asynchrones fonctionnent selon un modèle requête-acceptation-notification : lorsque le client envoie la requête, le serveur répond en confirmant qu’il a bien pris en charge l’opération. Le code de réponse typique est « 202 Accepted », et la réponse contient généralement aussi un ID permettant de récupérer le résultat final lorsqu’il sera disponible. À ce moment-là, le client est libre de gérer d’autres requêtes (on parle d’un mécanisme « non bloquant »).
Une fois l’opération traitée, le serveur transmettra la réponse au client. Cela peut se faire de deux manières :
- Polling : le client interroge périodiquement l’état du serveur jusqu’à ce que la réponse soit disponible (modèle Pull) ;
- Callback / Webhook : lorsque la réponse est prête, le serveur appelle une URL du client pour l’informer de la fin de l’opération (modèle Push).
Les API asynchrones sont essentielles dans les scénarios où les temps de réponse sont longs, comme le traitement de vidéos ou de documents. Leur principal avantage est l’absence totale de temps d’attente, ce qui permet d’optimiser l’utilisation des ressources de calcul et de réseau. En contrepartie, les flux asynchrones sont plus complexes à configurer, notamment parce qu’ils nécessitent la gestion des notifications.
Les différences entre API synchrones et asynchrones
Pour résumer les différences entre API synchrones et asynchrones, on peut dire qu’elles portent sur :
- Flux de travail : les API synchrones bloquent le client en attendant la réponse, alors que les API asynchrones lui donnent les références pour « récupérer » la réponse et le libèrent immédiatement ;
- Cas d’usage : les API synchrones conviennent aux opérations brèves et rapides, tandis que les API asynchrones sont préférables pour les traitements qui durent plus de quelques millisecondes ou qui nécessitent des files de travail ;
- Livraison de la réponse : dans les API synchrones, la réponse est fournie immédiatement, tandis que dans les API asynchrones, elle est transmise via des mécanismes de notification ultérieurs (polling ou callback) ;
- Complexité : les API asynchrones sont plus complexes à implémenter, car elles doivent gérer l’état de l’opération dans le temps et nécessitent des mécanismes de notification à partager avec le client (qui doit par exemple gérer les cycles de polling ou exposer un endpoint de callback).
De nombreuses applications modernes utilisent des architectures hybrides où API synchrones et asynchrones coexistent selon les besoins. Dans un e-commerce, par exemple, des opérations comme la vérification du panier et l’autorisation de paiement utilisent une communication synchrone, tandis que les opérations suivantes — comme l’envoi de l’email de confirmation ou la génération de la facture — se déroulent de manière asynchrone.
Quand utiliser les API synchrones et asynchrones
Le choix entre API synchrones et asynchrones dépend essentiellement du temps d’exécution de l’opération et de la nécessité d’une réponse immédiate côté client. Si le client doit obtenir la réponse avant de continuer, la communication synchrone est préférable. Parmi les cas typiques, on trouve les processus d’authentification, où le serveur doit immédiatement vérifier les identifiants, ou la récupération de données en temps réel, nécessaire par exemple pour charger des images ou récupérer les métadonnées d’un produit dans une page e-commerce.
Les API asynchrones sont incontournables pour toute opération dont le traitement dure plus de quelques millisecondes. Parmi les exemples courants, on trouve le traitement de fichiers volumineux, dont la conversion ou l’importation peut être effectuée en arrière-plan pendant que le client fait autre chose, ainsi que l’envoi de courriers électroniques en masse, qui est immédiatement pris en charge puis traité progressivement.
Si le traitement peut avoir lieu en arrière-plan sans bloquer le client et qu’aucun retour immédiat n’est nécessaire, l’architecture asynchrone est la solution la plus efficace, en particulier dans les environnements traitant un grand volume de ressources, comme les plateformes de trading boursier où l’agrégation de données historiques demande du temps sans devoir bloquer les opérations en temps réel.
ARTICLES CONNEXES
Énergie sans carbone pour notre nuage ![]() Low CO2
Low CO2





Openapi SpA Unipersonale - Société soumise à la direction et au contrôle de Open Holding Srl - Viale Filippo Tommaso Marinetti 221 - 00143 Rome - Registre des Entreprises REA 1378273 - Capital social € 50.000,00 entièrement versé – N° TVA IT12485671007 - Code destinataire 'USAL8PV' - PEC : 
Openapi est certifiée : Système de gestion de la qualité UNI EN ISO 9001:2015 - Qualité des données ISO 25012:2014 - Gestion de la sécurité ISO/IEC 27001:2022 - Égalité des sexes selon UNI PdR 125:2022
Tous les prix sont à considérer hors TVA éventuelle, droits de timbre éventuels, frais de secrétariat et/ou taxes ou impôts autrement désignés s'ils sont dus. Tous les logos mentionnés sur le portail sont protégés par des droits d'auteur et appartiennent à leurs propriétaires respectifs.








