Qu’est-ce que le format TOON (Token-Oriented Object Notation)
Comment fonctionne TOON (Token-Oriented Object Notation), le format de données compact qui réduit jusqu’à 60 % les tokens dans les invites d’IA par rapport à JSON.

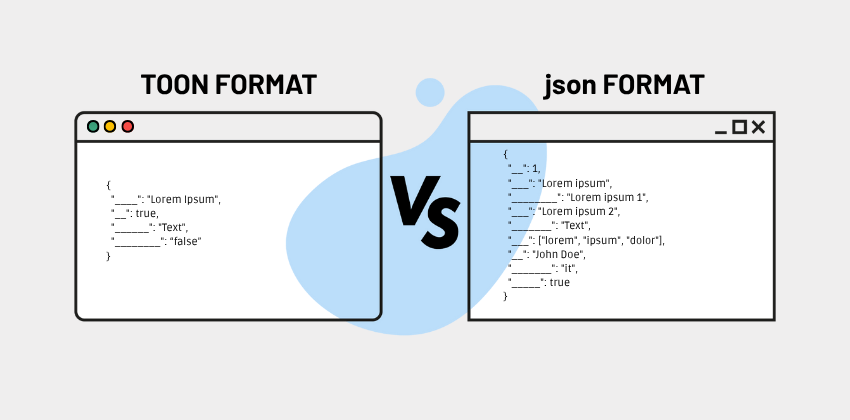
Table des matières
- Comment TOON peut changer la manière dont l’IA « voit » les données
- Pourquoi TOON est important aujourd’hui
- Qu’est-ce que TOON : définition et principes
- Comment fonctionne le format TOON
- Comment fonctionne TOON (pour ceux qui ne veulent pas entrer dans le code)
- Quels sont les avantages de TOON ?
- Quand TOON est-il particulièrement utile ?
- Quand ne pas utiliser TOON
- Comment utiliser TOON dans les prompts LLM
- Existe-t-il des outils simples pour utiliser TOON ?
- État actuel du projet TOON et feuille de route
- Points de vigilance : ce qui n’est pas encore confirmé
Comment TOON peut changer la manière dont l’IA « voit » les données
Dans le monde de l’intelligence artificielle moderne, en particulier lorsqu’on utilise des modèles de langage de grande taille (Large Language Models, LLM), chaque token compte. Le coût d’une API, ainsi que la latence et l’efficacité du prompt, dépendent directement du nombre de tokens envoyés au modèle. C’est dans ce contexte qu’émerge TOON (Token-Oriented Object Notation), un format de sérialisation compact, lisible et spécialement conçu pour minimiser le nombre de tokens nécessaires à la représentation de données structurées.
Au lieu d’utiliser le format JSON classique (ou d’autres), TOON « compacte » les mêmes informations de manière plus légère et optimisée, tout en restant facilement lisible par un être humain.
Examinons plus en détail ce qu’est TOON, pourquoi il est utile, comment il fonctionne, ses limites et son état actuel.
Pourquoi TOON est important aujourd’hui
Le problème avec JSON dans les flux IA
JSON est largement utilisé pour représenter des données structurées. Mais sa grammaire est « verbeuse » : accolades { }, crochets [ ], guillemets ", virgules, indentation… tout cela génère des tokens supplémentaires lorsqu’on envoie des payloads à un LLM.
Dans les cas où l’on manipule de nombreux objets uniformes (par exemple une liste d’utilisateurs, de produits, de lignes), les clés se répètent continuellement, augmentant encore le poids en tokens.
La solution ? TOON !
TOON a justement été créé pour résoudre ce problème : c’est un format conçu pour maximiser l’efficacité en tokens tout en conservant la lisibilité humaine et la structure sémantique complète du JSON. Selon plusieurs benchmarks, TOON peut réduire l’usage de tokens de 30 à 60 % par rapport au JSON traditionnel. Cette réduction se traduit par des coûts API plus faibles, davantage d’espace dans la fenêtre de contexte du modèle et, dans certains cas, une meilleure précision dans la compréhension des données par le LLM.
Chez Openapi nous travaillons également en ce sens et, très prochainement (dès les prochaines semaines), nos API prendront aussi en charge le nouveau format.
Qu’est-ce que TOON : définition et principes
TOON est l’acronyme de Token-Oriented Object Notation. Il s’agit d’un format de sérialisation textuelle pour les données structurées, conçu spécifiquement pour être envoyé à des LLM en entrée. TOON est :
- Compact et efficace en tokens : il élimine de nombreux éléments syntaxiques redondants du JSON.
- Sensible au schéma (schema-aware) : il utilise des déclarations explicites de longueur de tableaux et de champs pour formaliser davantage la structure.
- Lisible par l’humain : il reste lisible pour les développeurs grâce à une indentation similaire au YAML.
- Tabulaire pour les tableaux uniformes : pour les tableaux où tous les objets possèdent les mêmes champs, TOON utilise une structure en tableau (en-tête + lignes) proche du CSV.
Selon le dépôt officiel sur GitHub, TOON est sans perte par rapport au JSON : on peut convertir des données JSON → TOON → JSON sans aucune perte d’information.
Comment fonctionne le format TOON
Syntaxe de base
1. Objets simples
TOON élimine les accolades et utilise l’indentation pour imbriquer les éléments.
Par exemple :
id: 123 name: Ada active: true Cela représente l’objet JSON suivant :
{ "id": 123, "name": "Ada", "active": true }2. Objets imbriqués
En utilisant une indentation similaire à YAML :
user: id: 123 name: AdaReprésentation en JSON :
{ "user": { "id": 123, "name": "Ada" } } 3. Tableaux de primitives (« primitive array »)
TOON déclare la longueur et les valeurs en ligne :
tags[3]: foo,bar,baz Cela équivaut à :
["foo", "bar", "baz"] en JSON.
4. Tableaux d’objets uniformes (tabular array)
C’est la partie la plus puissante en termes d’économie de tokens :
users[2]{id,name,role}: 1,Alice,admin 2,Bob,user - users[2] : indique un tableau de 2 éléments
- {id,name,role} : les clés (champs) que chaque objet possédera
Les lignes suivantes contiennent les données séparées par des virgules, une ligne par objet.
5. Options de délimiteurs
Pour séparer les valeurs dans les lignes, TOON prend en charge divers délimiteurs : virgule (,), tabulation (\t) ou pipe (|). L’utilisation de tabulations ou de pipes peut offrir des économies de tokens supplémentaires, car elle réduit la nécessité de guillemets ou d’échappement.
6. Key folding (regroupement des clés)
La spécification TOON prévoit l’option de « key folding » : si une structure comporte des chaînes de clés à un seul niveau (« wrapper » à clé unique), elles peuvent être représentées sous forme de chemins pointés pour économiser des tokens.
7. Quotation des chaînes
Les chaînes en TOON ne sont guillemetées que lorsque cela est nécessaire : par exemple si elles contiennent le délimiteur actif, deux points :, espaces initiaux/finals, caractères de contrôle, etc.
8. Conversion de types spéciaux
- Nombres : formatés en notation décimale (par ex. pas en notation scientifique).
- NaN ou ± Infinity deviennent null.
- BigInt : si dans la plage sûre, converti en nombre ; sinon représenté comme une chaîne décimale guillemetée.
- Dates : converties en chaînes ISO guillemetées.
- Valeurs non sérialisables généralement converties en null
Comment fonctionne TOON (pour ceux qui ne veulent pas entrer dans le code)
Pour ceux qui ne sont pas développeurs, il suffit de considérer TOON comme un langage plus « léger » pour décrire les données.
Lorsqu’il faut envoyer un groupe d’éléments tous similaires (par exemple une liste d’utilisateurs avec nom, âge, rôle), TOON permet de déclarer une seule fois quels champs existent (nom, âge, rôle), puis de fournir les données ligne par ligne. Ainsi, il n’est plus nécessaire de réécrire « nom », « âge », « rôle » pour chaque utilisateur, comme il faudrait le faire dans le JSON classique — ce qui économise des « carburants » (tokens). Lorsque les données sont simples (par exemple une liste de tags ou de mots), TOON les représente de manière compacte : moins de symboles, moins de « ponctuation inutile ». Pour les données imbriquées (par exemple un objet dans un autre), TOON utilise l’indentation (des espaces) pour représenter la hiérarchie, comme dans un document bien organisé, mais sans lourdes accolades.
En bref : TOON conserve la structure logique des données, tout en réduisant les « mots vides ».
Quels sont les avantages de TOON ?
Voici les avantages liés à l’utilisation du format TOON :
1. Efficacité en tokens
Grâce à sa syntaxe minimale, à la déclaration unique des clés et à la structure tabulaire, TOON permet une économie moyenne de 30 à 60 % des tokens par rapport au JSON. Cette économie est particulièrement significative dans les flux LLM où l’on envoie des données tabulaires répétitives.
2. Meilleure précision (guardrails schema-aware)
TOON n’est pas seulement compact : il est sensible au schéma. Déclarer la longueur d’un tableau ([N]) et les champs ({…}) aide les LLM à mieux valider la structure, réduisant les risques d’erreurs, d’omissions ou d’« hallucinations » lorsque le modèle doit raisonner sur des données structurées. Les benchmarks du dépôt officiel montrent que TOON peut obtenir une retrieval accuracy supérieure à celle du JSON compact.
3. Lisibilité humaine
Malgré la réduction de symboles, TOON reste lisible pour les développeurs grâce à son indentation, son organisation tabulaire et une syntaxe claire. Cela facilite le debugging, la rédaction manuelle de prompts et l’interprétation par les prompt engineers.
4. Compatibilité et absence de perte d’information
TOON est sans perte par rapport au JSON : toute structure JSON peut être représentée en TOON et reconvertie sans aucune perte. Il existe des bibliothèques et des SDK pour encoder (encode) et décoder (decode) entre JSON et TOON dans différents langages (ex. TypeScript, Elixir, PHP).
5. Implémentations multi-langages
TOON n’est pas qu’une idée abstraite : il existe déjà de nombreuses implémentations :
- TypeScript / JavaScript : le dépôt officiel inclut un SDK TypeScript
- Elixir : implémentation TOON pour Elixir
- PHP : port TOON pour PHP
- R : package CRAN pour sérialiser des objets R en TOON
D’autres langages continuent d’arriver grâce à la nature open-source de la spécification.
Quand TOON est-il particulièrement utile ?
TOON apporte le plus grand bénéfice dans certains scénarios types :
- Listes d’éléments similaires : lorsque de nombreux objets partagent les mêmes champs (ex. liste d’utilisateurs, commandes, produits). C’est ici que l’économie de tokens est la plus évidente.
- Prompts pour IA : lorsqu’on interagit avec un modèle IA et qu’on doit lui transmettre des données structurées, TOON aide le modèle à mieux les interpréter, avec moins de surcharge.
- Situations où le coût des tokens est critique : si l’on paie à la consommation (comme c’est le cas pour la plupart des API IA), TOON peut réduire fortement la facture.
- Debug ou modifications de données lisibles : pour ceux qui construisent ou ajustent des données, la lisibilité de TOON facilite la compréhension par rapport à un JSON très minifié.
Quand ne pas utiliser TOON
Il est important de souligner que TOON n’est pas toujours le choix idéal. Certains cas favorisent d’autres formats :
- Structures très imbriquées ou hétérogènes : si les données ont de nombreux niveaux d’imbrication ou si les tableaux contiennent des objets avec des champs différents, l’économie en tokens peut diminuer, voire être pire que le JSON compact.
- Données purement tabulaires et simples : pour des données plates (table simple), le CSV peut être plus compact que TOON, car TOON ajoute des métadonnées (longueur, noms des champs).
- Applications où la latence est critique : dans les scénarios où le temps de sérialisation/désérialisation est prioritaire, JSON compact peut être plus rapide — même s’il utilise davantage de tokens.
Comment utiliser TOON dans les prompts LLM
Encodage avant l’envoi
On peut utiliser les bibliothèques officielles pour convertir des objets JSON en TOON : par exemple avec le package TypeScript officiel (@toon-format/toon)
Lors de la construction du prompt, inclure le TOON sérialisé dans un bloc de code, par exemple :
toon users[3]{id,name,role}: 1,Alice,admin 2,Bob,user 3,Charlie,user Cela aide le modèle à reconnaître la structure et à répondre de manière cohérente.
Génération de TOON par le LLM
Si l’on souhaite que le modèle génère des données en TOON, on peut :
- Montrer un exemple d’en-tête TOON (comme users[N]{…}:)
- Spécifier que le modèle doit produire les lignes correspondantes et le nombre [N] correct
- Exiger une réponse uniquement dans le bloc de code et au format TOON
Ce schéma est utile car le modèle n’a pas besoin de « deviner » les noms des clés : ils sont déjà déclarés.
Existe-t-il des outils simples pour utiliser TOON ?
Il n’est pas nécessaire d’être expert en programmation pour essayer TOON. Des outils existent pour ceux qui ont des données mais ne souhaitent pas écrire du code complexe :
- Convertisseurs web : il existe des sites où coller ses données (JSON ou CSV) permet d’obtenir automatiquement leur version TOON optimisée, directement dans le navigateur.
- Playgrounds interactifs : certains outils permettent de visualiser en temps réel le nombre de tokens occupés par le format.
- Outils sécurisés : des applications côté client (dans le navigateur) réalisent la conversion sans envoyer les données à des serveurs externes, garantissant une meilleure confidentialité.
État actuel du projet TOON et feuille de route
Le projet TOON est actif et open-source. Le dépôt officiel sur GitHub inclut la spécification, le code et les benchmarks. La spécification officielle (spec) est à la version 2.0 (working draft) et disponible. Il existe déjà des implémentations dans de nombreux langages (TypeScript, Elixir, PHP, R, etc.), et d’autres pourraient suivre. Des outils et convertisseurs web (ex. ToonParse) permettent de convertir JSON → TOON et inversement, côté client, sans envoyer les données à des serveurs externes. Les benchmarks indiquent que TOON réduit non seulement les tokens, mais peut également améliorer la retrieval accuracy lorsqu’on utilise des LLM sur des données structurées.
Points de vigilance : ce qui n’est pas encore confirmé
Comme l’ont souligné certains commentaires dans la communauté, beaucoup de LLM n’ont pas été « entraînés » sur TOON : les données d’entraînement proviennent presque entièrement de JSON ou d’autres formats. Cela signifie que l’utilisation de TOON peut nécessiter des ajustements, et dans certains cas le modèle peut répondre de manière moins optimale s’il n’est pas familiarisé avec la structure. Bien qu’open-source et en développement rapide, TOON reste relativement nouveau. La spécification évolue encore, et certaines implémentations peuvent ne pas être parfaitement compatibles entre elles si elles ne suivent pas la bonne version de la spec.
En définitive (ou en résumé)
TOON (Token-Oriented Object Notation) représente une innovation majeure dans la sérialisation des données pour les applications LLM. Grâce à sa structure compacte, lisible par l’humain et sensible au schéma, il permet de réduire drastiquement le nombre de tokens par rapport au JSON traditionnel (souvent jusqu’à 60 %) tout en conservant la pleine sémantique et structure des données.
Cependant, il est important de rester réaliste : tous les scénarios ne sont pas encore adaptés à TOON. Pour l’instant, TOON est un outil complémentaire au JSON : utile lorsque l’économie de tokens a un impact économique ou technique, mais pas encore un substitut universel.
Si vous êtes développeur travaillant avec des LLM, TOON mérite d’être exploré : il peut servir à construire des prompts plus efficaces, optimiser les coûts API et augmenter l’espace utile dans la fenêtre de contexte du modèle. Mais adoptez une approche pragmatique : mesurez toujours les bénéfices dans votre cas d’usage et testez la fiabilité de la conversion JSON ↔ TOON dans votre pipeline.
Openapi s’apprête à prendre en charge TOON dans ses API, et c’est une nouveauté très importante : cela signifie que les applications s’appuyant sur ces API pourront devenir plus efficaces et moins coûteuses, en exploitant un format moderne et optimisé.
ARTICLES CONNEXES
Énergie sans carbone pour notre nuage ![]() Low CO2
Low CO2





Openapi SpA Unipersonale - Société soumise à la direction et au contrôle de Open Holding Srl - Viale Filippo Tommaso Marinetti 221 - 00143 Rome - Registre des Entreprises REA 1378273 - Capital social € 50.000,00 entièrement versé – N° TVA IT12485671007 - Code destinataire 'USAL8PV' - PEC : 
Openapi est certifiée : Système de gestion de la qualité UNI EN ISO 9001:2015 - Qualité des données ISO 25012:2014 - Gestion de la sécurité ISO/IEC 27001:2022 - Égalité des sexes selon UNI PdR 125:2022
Tous les prix sont à considérer hors TVA éventuelle, droits de timbre éventuels, frais de secrétariat et/ou taxes ou impôts autrement désignés s'ils sont dus. Tous les logos mentionnés sur le portail sont protégés par des droits d'auteur et appartiennent à leurs propriétaires respectifs.








